NTT版LLM(大規模言語モデル)「tsuzumi 2」を活用した電力業務特化型LLMの構築および検証を開始
<イメージ図>【写真詳細】
中国電力株式会社(本社:広島県広島市、代表取締役社長執行役員:中川賢剛、以下「中国電力」)とNTTドコモビジネス株式会社(旧 NTTコミュニケーションズ株式会社、本社:東京都千代田区、代表取締役社長:小島克重、以下「NTTドコモビジネス」)は、このたび共同で、NTT株式会社が開発した大規模言語モデル※1(以下「LLM」)「tsuzumi 2※2」を活用した電力業務特化型LLMの構築および検証を開始しましたのでお知らせします。
1.背景と目的
電力会社では、法令や各官公庁の規制など、多岐にわたる分野で厳格な基準に則った業務遂行が求められます。特に公的機関へ提出する書類は規制等に準拠していることが不可欠であり、中国電力においては、これらの資料作成・確認業務に多くの時間を要していました。この課題を解決するため、中国電力とNTTドコモビジネスはこれまで、主に資料の作成・確認業務における業務効率化・品質向上を目的とした生成AIアプリケーション(以下「AIアプリ」)の開発および業務適用に、共同で取り組んできました。
この中で、AIアプリの開発においてRAG※3などの汎用的な技術では、電気事業に関する専門知識や中国電力固有の業務情報について正確に回答生成・判断することが難しく、実務での利用に十分な精度を確保できないケースがありました。
こうした課題を踏まえ、日本語に強みを持つ純国産のLLM「tsuzumi 2」に電気事業や中国電力の業務データを学習させることで、より実務的かつ高度な回答生成や独自の業務ルールに基づいた判断を支援する電力業務特化型LLMを新たに構築し、実用化を目指すこととしています。
2.取り組みの概要
本取り組みでは、「tsuzumi 2」に中国電力の業務情報やノウハウなど、実務的な観点で選定したデータを学習させることで、電力業務に特化したLLMの構築と検証を実施します。本年1月から3月末にかけて次のプロセスで取り組み、構築したLLMの精度等を踏まえて2026年度以降の実用化を目指します。
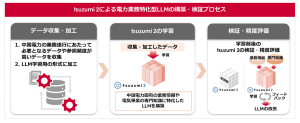
(1)データ収集・加工
中国電力が同社の社内マニュアルや手引、過去の行政機関への申請書類など、業務遂行にあたって必要となるデータや参照頻度が高いデータを中心に収集します。その後、NTTドコモビジネスが、データをLLM「tsuzumi2」の学習に適した形式へ加工します。
(2)「tsuzumi 2」の学習
NTTドコモビジネスが、(1)で加工したデータやインターネット上の公開情報等を「tsuzumi 2」に学習させ、電気事業や中国電力固有の業務情報に特化したLLMを構築します。
(3)検証・精度評価
中国電力が、業務で調べる機会が多い事項等をまとめたQA集を作成した上で、学習前後の「tsuzumi 2」に対して、電気事業共通の専門用語や中国電力固有の業務情報等にどの程度正確に回答できるかを確認し、精度の比較・分析を実施します。その後、NTTドコモビジネスが、中国電力の精度評価を踏まえ、「tsuzumi 2」に再学習を行い、LLMの精度を改善します。
<イメージ図>
画像1: https://www.atpress.ne.jp/releases/570779/img_570779_1.png
3.両社の役割
・中国電力
-電気事業や中国電力固有の業務情報等の学習用データ収集・提供
-精度評価用QA集の作成
-学習前後のLLMの精度評価
・NTTドコモビジネス
-学習用データの加工
-「tsuzumi 2」の学習
-中国電力の精度評価を踏まえたLLMの改善(再学習)
4.今後の展開
本取り組みを通じて、中国電力においては、より高度かつ幅広な業務領域での生成AI活用を進めることでDXを加速させ、エネルギアグループDX戦略※4で掲げたAIによる業務変革の実現に取り組みます。
NTTドコモビジネスにおいては、LLMの学習などの過程で得られた知見を活かし、電力業界特有の知識やルールに対応したアプリケーション開発を進め、将来的にはIOWN※5などの先進技術と連携した生成AIアプリプラットフォームを構築し、地域・産業のDX促進と共創型ビジネスの拡大を目指します。
両社は、今後も密に連携しながら本取り組みを継続し、電力業務特化型LLMを改善していくことで、エネルギー業界における新たな価値創造を目指してまいります。
※1:大規模言語モデル(LLM:Large Language Models)は、言語の理解や文章の生成に優れた能力を持つ、大量のテキストデータを使って学習された言語モデル。また、言語モデルとは、言語データを学習し、その統計的な傾向をもとに適切な言葉の並びや文章の構造を予測するためのAI技術を指す。
※2:tsuzumi (R)はNTT株式会社の登録商標。tsuzumiの次世代モデル「tsuzumi 2」は、日本語に強みを持つ純国産の大規模言語モデルとして開発されている。
https://www.rd.ntt/research/LLM_tsuzumi.html
※3:RAG (Retrieval-Augmented Generation)は、大規模言語モデルによるテキスト生成時に、外部情報を活用して推論の精度を高める技術。
※4:中国電力グループ全体での生産性向上と新たな価値創造を加速することを目的に策定。2030年度に向けたデジタル技術活用に関する目指す姿と取り組みの視点を示すもの。
https://www.energia.co.jp/press/2025/16170.html
※5:IOWN (Innovative Optical and Wireless Network)構想とは、NTTが提唱する次世代情報通信基盤。
https://group.ntt/jp/group/iown/
「IOWN(R)」は、日本電信電話株式会社の商標又は登録商標。
プレスリリース情報提供元:@Press
スポンサードリンク
中国電力株式会社 NTTドコモビジネス株式会社の記事





















その他の最新プレスリリース
- 「docomo business RINK(R) WANセキュリティ」においてサプライチェーン・企業グループ全体を守る「脅威情報共有」の提供開始

- 特許出願につながる発明提案の質と効率を高める「アイデアシート作成支援AIエージェント」の提供を開始
- NTTドコモとNTTドコモビジネス、米沢市との災害連携協定を締結
- ひたちなか市と地域活性化および市民サービスの向上を目的とした包括的連携協定を締結
- 京都中央信用金庫、「エクサベース ロープレ」を導入し職員の応対力向上に向けたAI活用型研修を実施
- 世界149言語対応のAI通訳電話「tel-trans」をAndroidアプリストアで世界へリリース
- 火力発電所における巡視点検のスマート化に向けた取り組みについて
- 「docomo business ANCAR(R) Routing」を宮城県岩沼市役所に導入
- 国内初、NTTドコモビジネスが Nutanixソフトウェア の「完全従量課金」クラウドサービスを提供開始
- Spelldata、仙台計測センターを開設 東北地方からWeb・API通信の監視を開始

















